Cutting JBoss Incident MTTR with AI-Powered Root Cause Analysis
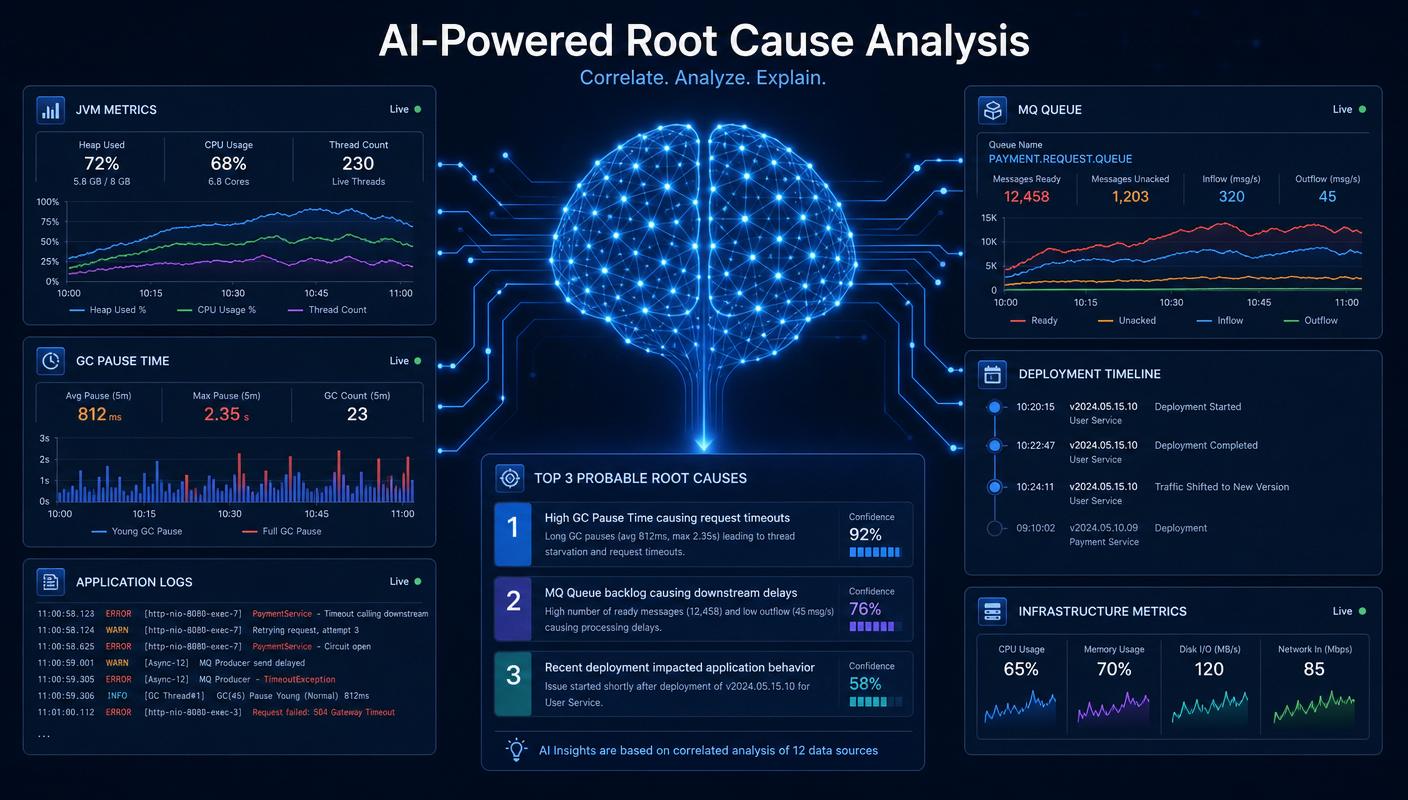
Most JBoss incidents in BFSI environments are not caused by exotic failures. They are caused by familiar patterns — a GC pause that lengthens under load, an MQ consumer that silently falls behind, a configuration change that quietly diverges between two cluster members, a memory leak that only manifests after a long-running deployment. The problem is rarely that the signals are missing. The problem is that the signals are scattered across consoles, logs, dashboards and chat threads when the on-call engineer needs them most.
What AI-powered RCA actually does
An AI-powered root cause analysis engine, in the JBoss context, is not a chatbot bolted onto a monitoring tool. It is a layer that continuously correlates JVM-level metrics, GC behaviour, log patterns, deployment events, MQ throughput and EJB invocation telemetry, then reasons about which of those signals best explains a given symptom. When an alert fires, the engineer should not see a wall of green and red tiles — they should see a short, ranked list of probable causes with the supporting evidence already attached.
Where AI shortens the timeline
- Triage: instead of opening five tools, the on-call engineer starts from a single hypothesis with linked evidence.
- Pattern recognition: recurring anomalies — the same EJB pool exhaustion that happened last quarter, for example — are surfaced with historical context.
- Plain-language tuning advice: GC and heap recommendations are explained in operator language, not raw JVM flags.
- Change correlation: recent deployments and configuration drifts are automatically considered as candidate causes.
- Knowledge retention: junior engineers benefit from institutional memory baked into the platform rather than tribal knowledge.
Realistic expectations
AI does not eliminate the need for skilled JBoss engineers. Complex incidents — particularly those involving distributed transactions, network partitions or upstream dependency failures — still require human judgement. What AI does is compress the diagnostic phase. The reductions in mean time to resolution that BFSI teams typically report after adopting AI-assisted RCA are significant, often in the high double digits, but the magnitude depends heavily on baseline observability maturity. Teams already running structured logging and consistent JVM telemetry see the biggest gains soonest.
Designing for trust
For BFSI operators, an AI recommendation is only as useful as the evidence behind it. That is why every AI-generated explanation in a serious operations tool should link directly back to the underlying metrics, log lines or configuration diff that drove it. The operator stays in control; the AI accelerates judgement instead of replacing it. This is also what compliance teams want to see: clear, reviewable reasoning chains, not opaque automated actions.
Where to start
Teams getting the most out of AI-powered RCA start narrow. Pick the two or three incident classes that dominate your post-mortems — GC pauses, MQ lag, configuration drift — and measure how much faster the AI-augmented workflow resolves them compared with the existing runbook. Once those wins are visible, broader rollout across environments and incident classes becomes a much easier conversation with risk and audit.